Importance of Data Data Management and Analytics
Data Mining
Why Data Mining?
We are living in a data overloaded world. Just imagine the amount of data that might be getting collected in a new generation banks every second. The amount of data being collected is tremendously increasing day by day mainly due to technological advancements. Today the technology is so advanced that it is very easy and cheap to collect and store data. Having large amounts of data in databases might not be useful if the required information is not at our finger tips at the exact time we need it. Today’s competitive world demands instant access to information at any cost. To stand out from the crowd, organizations might require customer demographics, stock value information, sales related information and so on for decision making, customer relationship management, market analysis, market segmentation etc. So organizations are finding new methods to locate, analyze and extract interesting and useful information from the available data. In short, businesses and organizations are drowning in data, but starving for information. Here comes, data mining into picture.
What is Data Mining?
Data mining is the process of analyzing large amount of data from different perspectives and extracting hidden patterns of potentially useful and previously unknown information. The data used for analysis could be available in text files, databases, data warehouses, World Wide Web and/or other information storehouses. The information extracted through data mining can be used for making better business decisions and hence gain competitive edge. Data mining can be used to get answers to complex business related queries. For example, a retailer can get answer to questions like “What products my customers buy together?”, “What new products can be developed for a specific group of customers?”, “How the promotions improved my business?” etc easily, quickly and accurately with the help of data mining.
You might have heard how the Midwest Grocery chain used the possibilities of data mining to increase their business. They found that men who buy diapers on Thursdays and Saturdays tend to buy beer as well. They also discovered that most of the customers prefer to shop on Saturdays more comfortably than other days. Though the findings might be really strange, the Midwest group could utilize this information efficiently to increase their profit. They moved their beer display near to diapers so that they can ensure that customers get both the products easily. They also could arrange more products and promotions on Saturdays which boosted their sales and profit. This is a simple example of data mining.
Data Mining Processes
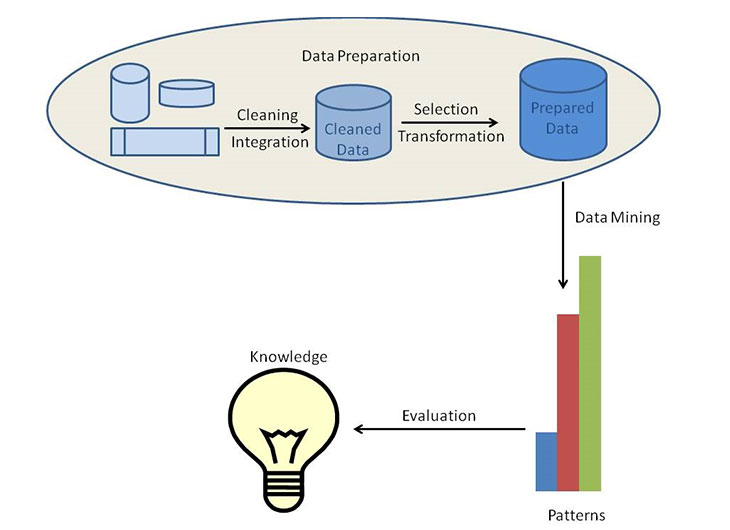
Both the terms Knowledge Discovery in Databases (KDD) and Data Mining are used synonymously most of the time. In fact, data mining and KDD are not exactly the same. The KDD includes different processes such as data cleaning, data integration, data selection, data transformation, data mining, pattern evaluation and knowledge presentation. However, it is obvious that data mining cannot be completed without cleaning, integrating, selecting and transforming the data. Thus, data cleaning, data integration, data selection and data transformation are considered as the pre-processing steps of data mining.
Of course, data that needs to be analyzed comes in different formats. So, it is highly necessary to remove noise and inconsistent data before storing them so that the data is clean and reliable. This process is known as data cleaning. During data integration, the cleaned data from multiple data resources may be combined. The next is the data selection process. The data repository would be containing large amounts of data, which may or may not be relevant to the specific analysis. So, the data which is relevant for the specific task is retrieved from the database. During data transformation, data is transformed and consolidated into appropriate forms suitable for mining.
Now the data is ready for data mining. Data mining applies wide variety of methods to extract data patterns. Finally, the mined information is presented to the end user with the help of different visualization and knowledge representation techniques so that he will be able to easily understand what he was looking for.
Data Mining Tasks
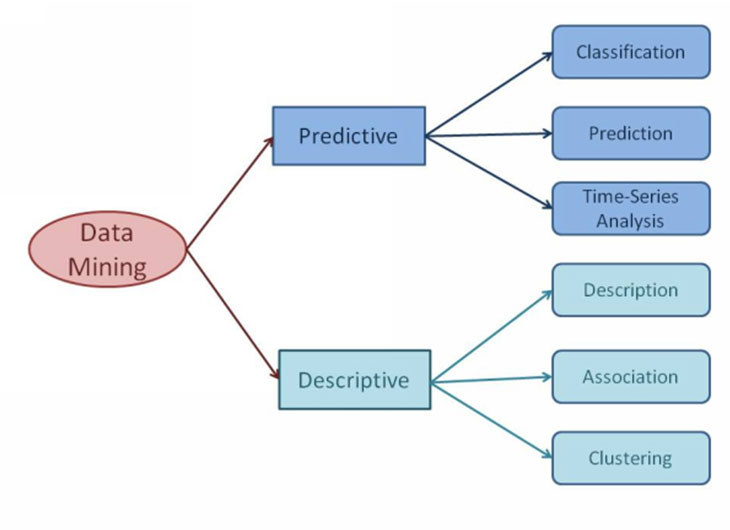
The data mining tasks are generally classified into two types: predictive data mining and descriptive data mining. Predictive model performs inference on the available data and tries to predict how a new data set will behave whereas descriptive model describes the data set concisely by extracting representative information about data.
A data mining system can execute one or more of the tasks such as class description, association, classification, prediction, clustering or time-series analysis. All these tasks fall into either predictive data mining or descriptive data mining. Class description provides a comprehensive summarization of a data set and distinguishes it from others. So, you can use class description to compare sales of two regions or to identify the factors that discriminate two results etc. Association finds out the association relationship among different items in a data set. Classification, as the name indicates, classifies a set of objects based on some specific features. Prediction tries to predict the possible values of some missing data analyzing the available data set. Clustering identifies collection of data objects that are homogeneous. Time series analysis finds certain regularities in the time-series data. Stock market analysis is an example of time series analysis.
Tools and Techniques
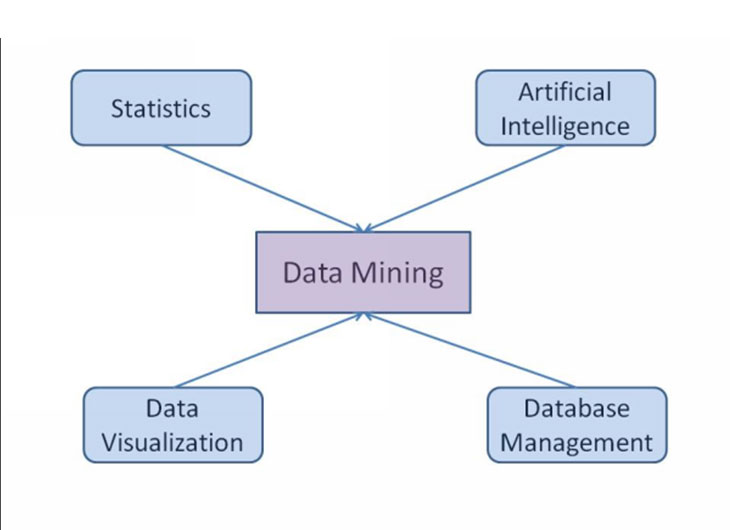
Data mining combines different techniques and tools from various disciplines such as machine learning, statistics, artificial intelligence, neural networks, database management, data warehousing, data visualization etc to get more accurate and reliable results. Statistics includes a number of methods to analyze numerical data in large quantities. Artificial intelligence and neural networks are very efficient in classification, prediction and clustering type of tasks. Database management and data warehousing techniques including indexing and data accessing help to deal with large quantities of data efficiently. Knowledge visualization techniques are equally important because the end user wants is just useful information that is easily understandable.
The main reason why data mining is more accurate than traditional data analysis is that traditional data analysis is assumption driven whereas data mining is discovery driven. To make it clear, in traditional data analysis, a hypothesis is formed which is validated against the data whereas in data mining, patterns are automatically extracted from data.
Data Mining Applications
Data mining can be applied in a number of areas such as business analysis and management, customer relationship management, risk analysis and management, computer security, bioinformatics and so on. Companies, that consider customer satisfaction as the major factor of their business success, make the best use of data mining. They try to identify how their internal affairs such as staff skills, price etc affect external factors like customer demographics, competition and so on. If this kind of information is utilized effectively, organizations can have positive affect on customer satisfaction, business profit, sales and so on. Retailers could analyze buying habits of consumers which can be used to connect with them in the correct way. For example, retailers could send targeted promotions, develop products that attract specific customer segments, suggest products at the right time and so on by mining the buying habits data. Banking and insurance organizations make use of data mining for risk analysis and management. Researches show that customer demographics such as education, occupation, age, income, gender etc affect the usage of credit cards. So, organizations can analyze customer demographics to manage risk.
Challenges in Data Mining
The main challenge that data mining goes through is that it has to extract information from data that could be in different formats and residing in different repositories. As data is the core of any data mining process, it needs to be accurate, complete and reliable. Most of the time, the data used for data mining is dirty, incomplete, inadequate, inaccessible and poorly represented. Hence, data cleansing is a real headache in the process of data mining. As we all know, the organizational data comes in different formats. The data could be text, multimedia, or even spatial data; it could be structured, semi structured or unstructured. Moreover, the data could be in databases, data warehouses, or web based data repositories. So, highly complex data mining techniques are required to get accurate results I case of data mining.
Summary
Data mining is the process of sorting through large amounts of data, extracting potentially relevant and previously unknown information and representing it in an understandable structure for further use. Data mining helps businesses in critical decision making process and hence to stand out from the crowd. In short, data mining enables organizations to learn from the past, organize the present and shape the future.